
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
Tags
- 이분탐색 #dp #11053
- 호반우 상인
- 투포인터 #백준 #boj #20922 #22862
- 3D #Reconstruction #computer #vision #volume #metric #tsdf #kinect #fusion
- graph #최단경로
- 코딩
- 최소 #공배수 #최대 #공약수 #유클리드 #호제법 #lcm #gcd #c++ #boj #3343 #백준 #장미
- 22869
- hcpc
- 16202
- 30870
- 백준 #다익스트라 #dijkstra #9370 #c++
- 백준
- graph
- boj #백준
- backtracking #codetree #디버깅 #삼성코테
- 1174
- 진법변환 #2to10 #10to2 #이진법 #십진법 #변환 #bitset #c++
- 레드아보
- 사이클 없는 그래프
- 쌤쌤쌤
- BOJ
- LIS #가장긴증가하는부분수열 #
- 줄어드는수
- N번째큰수
- c++ #boj #
- C++
- 3343
- 20117
- c++ #입출력 #속도 #ios #sync_with_stdio #cin #cout #tie
Archives
- Today
- Total
hyunjin
[1차원 배열 - 나머지(3052)] map 사용 - map 사용법 다시 읽어보기 본문
728x90
문제 간단 설명
10개의 수를 입력 받고 해당 수들을 42로 나눈 나머지를 구한다.
그 다음 서로 다른 값이 몇 개 인지 출력하는 문제
첫 번째 풀이 : map 사용
#include <iostream>
#include <map>
using namespace std;
int main(void) {
map <int, int> m;
int result = 0;
for (int i = 0; i < 10; i++) {
int num=0;
cin >> num;
if (m.count(num % 42) == 0) {
m.insert(make_pair(num%42,1));
result++;
}
}
cout << result << endl;
return 0;
}
시간 복잡도 계산 해보기
map의 삽입,삭제,탐색 모두 O(lon n)
전체는 전체 input이 n이라 하면 n번 반복문을 돌고 if문이 true가 되는 경우가 최대 n번이고 해당
if문 실행 시간이 계산이 어렵다. if문 실행 시간이 O(lon n)는 아니다. map에 들어간 자료개수가 변하니까.....
모르겠다.
두 번째 풀이 : 1차원 배열 사용
#include <iostream>
using namespace std;
int main(void) {
int nums[42] = { 0, };
int result = 0;
for (int i = 0; i < 10; i++) {
int num=0;
cin >> num;
if (nums[num%42]==0) {
nums[num % 42]++;
result++;
}
}
cout << result << endl;
return 0;
}
시간 복잡도 계산 해보기
n개의 input이라면 O(n)
첫 번째 풀이 전략
- 문제를 보자마자 string을 index로 사용하는 구조체를 사용해야겠다고 생각했다. 가장 먼저 떠오른 것이 map이다. 정렬 필요 없으니 hash map 사용할껄
- 그 다음 입력 받고 나서 42로 나눈 나머지가 map안에 있는지 count를 통해 확인하여 문제를 풀었다.
- 사실 42 크기의 int 배열을 만들어서 풀어도 되지만 남는 공간이 조금 아깝게 느껴졌다. map이 더 좋은 방법인지는 모르겠다. 이 문제에선 큰 차이는 없어보인다.

다른 사람 풀이
cin >> num;
if (!nums[num%42]++) {
result++;
}두 번째 풀이에서 루프 안에 조건문의 길이를 줄였다.
연산자의 우선 순위를 생각해보면 답이 나온다.
아래 사진을 보면 !(not) 연산자와 ++(증감) 연산자의 우선 순위가 같고,
해당 연산자는 오른쪽에 있는 것 부터 실행한다.
그리고 여기서 쓰인 증감 연산자는 후위 증감이므로 !num[]을 먼저 검사한 후 ++ 이 실행된다.
이 방법도 기억해두자.
배운 내용
1. map의 key 값 찾기 : find, count
map <string,int> m;
m.find("jack");
m.count("jack");1)find
map 전체에 처음으로 발견하는 key 값의 iterator 반환
2)count
있으면 1, 없으면 0 반환
2. 시간
1)hash map 탐색 속도 O(1)
배열로 접근하기 때문에
hash map은 자료가 정렬되어 저장되지 않음
2) map은 자료가 정렬되어 저장됨
3. 연산자 우선 순위
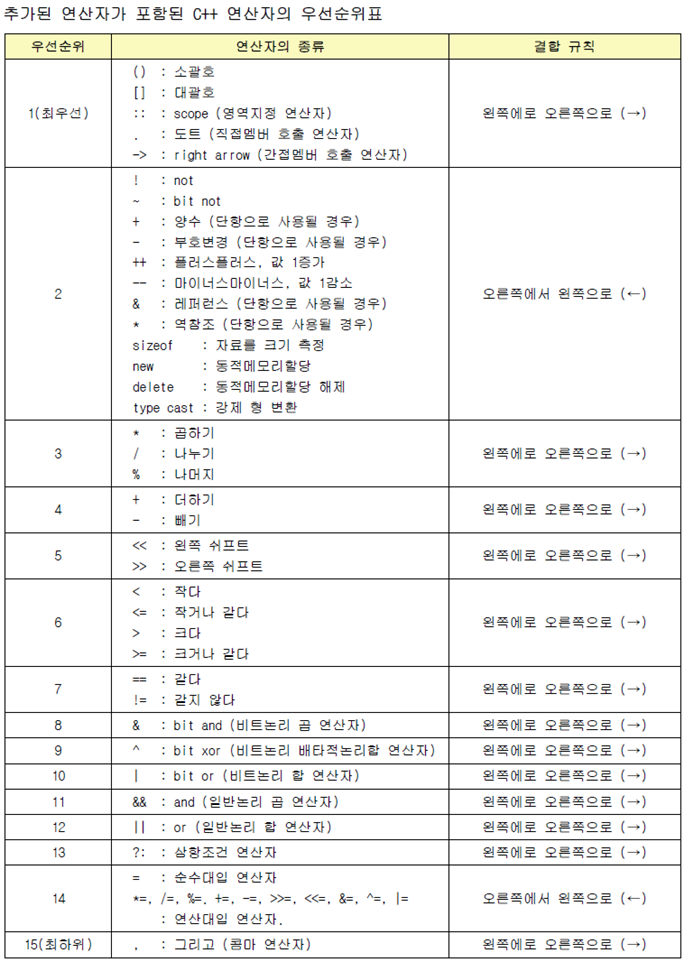
참고 사이트
728x90
'알고리즘 연습 > 프로그래머스' 카테고리의 다른 글
| [C++][해시/위장] unordered_map, 경우의 수,iterator (0) | 2020.08.31 |
|---|---|
| [level 2] 카펫 (0) | 2020.08.05 |
| [level 2] 카카오2020 문자열 압축 , substr (0) | 2020.07.20 |
| [level 1]다트 게임 (0) | 2020.07.20 |
| [level 1] 문자열 내 맘대로 정렬하기 , string compare, pair, sort (0) | 2020.07.14 |